算力霸主与数据之争 谁手握AI芯片与公共数据的未来?
在全球人工智能竞赛进入白热化的今天,拥有最多的AI芯片和人工智能公共数据的机构或国家,正掌握着定义技术未来的关键钥匙。这一问题的答案不仅关乎技术实力,更深刻影响着全球创新格局与地缘政治平衡。
AI芯片的算力版图:巨头角力与国家战略
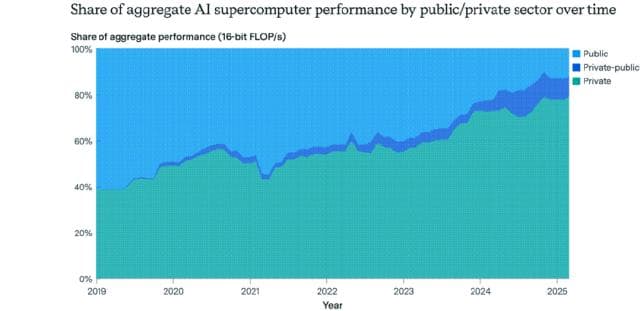
当前,全球AI芯片的集中度极高。从企业层面看,英伟达(NVIDIA) 凭借其GPU(尤其是专为AI训练设计的A100、H100等系列)的绝对领先优势,占据了全球AI训练芯片市场约80%的份额,是名副其实的“AI算力之王”。其客户囊括了全球主要的云服务商和大型科技公司。紧随其后的是AMD 和正在自研芯片的谷歌(TPU)、亚马逊(Inferentia/Trainium)、微软 以及特斯拉(Dojo) 等科技巨头,它们正试图在特定领域打破垄断。
而从国家与地区层面审视,美国 凭借其完整的半导体设计生态、核心IP(如Arm架构)以及英伟达、AMD、英特尔等领军企业,拥有全球最庞大、最先进的AI芯片设计与供给能力。中国企业在设计领域(如华为海思、寒武纪、地平线等)奋起直追,但在高端制造环节受制于外部制裁,整体算力规模与美国存在显著差距。欧盟、日本、韩国等也在加大投入,力图在下一代架构(如神经拟态芯片、光计算芯片)上寻求突破。
因此,若论“拥有最多”,英伟达是当前AI芯片(尤其是高端训练芯片)的全球最大持有者和供应商,而美国则是掌控AI算力产业链主导权的国家。
人工智能公共数据的“富矿”:开放、分散与治理挑战
与高度集中的芯片硬件不同,人工智能公共数据的“所有权”和“拥有量”更为分散和复杂。公共数据通常指由政府、公共机构、科研组织或开源社区收集和公开的,可供公众或研究使用的数据集。
- 政府与公共机构:美国、欧盟、中国 等主要经济体拥有海量的政府公开数据,涵盖地理信息、人口统计、气象、交通、科研文献(如美国的PubMed、arXiv)等领域。例如,欧盟通过《开放数据指令》推动公共部门信息的高价值再利用。中国政府也在大力推进公共数据资源的开放共享。这类数据规模巨大,是训练通用AI模型的重要基础。
- 国际组织与科研机构:如世界银行、联合国、欧洲核子研究中心(CERN) 等,在其专业领域产生并开放了极具价值的科学数据。人类基因组计划、大型天文观测项目(如Sloan Digital Sky Survey)产生的数据也是全球共享的宝贵资源。
- 科技公司与开源社区:谷歌、Meta、微软 等公司会开源部分数据集(如ImageNet由斯坦福团队创建但得到科技公司支持,COCO数据集由微软等贡献),以推动学术研究。Hugging Face等平台聚集了海量的开源模型和数据集。维基百科 作为全球最大的开放式网络百科全书,是多模态大模型文本预训练的核心语料来源之一。
很难界定单一实体“拥有”最多的公共数据。美国凭借其科技巨头、顶尖高校和联邦数据的综合开放程度,在高质量、高可用性AI公共数据的“生态丰富度”上暂时领先。但欧盟在数据治理规则(如GDPR)上引领全球,中国则拥有独特语言和文化场景下的庞大数据资源。
芯片与数据的共生关系:决胜未来的双重引擎
AI芯片(算力)与公共数据(燃料)构成了驱动人工智能发展的双引擎,二者缺一不可。
- 算力决定数据处理上限:没有强大的AI芯片,就无法高效处理PB乃至EB级别的公共数据,无法训练出更强大的模型。
- 数据决定AI智能的高度与广度:高质量、多样化、合规的公共数据是训练出公平、可靠、通用人工智能的基石。数据质量直接决定了模型性能的上限。
- 当前瓶颈与未来趋势:随着芯片性能提升和模型参数增长,高质量数据的稀缺性日益凸显,“数据荒”可能成为比“算力荒”更严峻的挑战。未来的竞争,将是“先进制程芯片” 与“高质量数据供应链” 的复合型竞争。各国正加紧建设国家级的公共数据开放平台和AI算力基础设施(如中国的“东数西算”),并围绕数据主权、跨境流动、隐私保护展开激烈博弈。
结论
在AI芯片领域,英伟达及背后的美国产业生态占据绝对优势;在人工智能公共数据领域,以美国科技生态、欧盟治理框架和中国规模场景为代表的多元力量共同构成了全球数据资源的拼图,无人能宣称完全“拥有”。未来的人工智能领导力,将属于那些能够有效整合顶尖算力、治理高质量数据、并构建开放创新生态的国家与联合体。这场竞赛不仅是技术的比拼,更是制度、合作与远见的较量。
如若转载,请注明出处:http://www.lazbhkeji.com/product/11.html
更新时间:2026-06-19 13:19:37